iMario vs SyntheticUsers.com: A Capability Comparison

If you are evaluating synthetic user research platforms in 2026, iMario and SyntheticUsers.com are likely both on your shortlist. They overlap on the surface promise: AI-generated participants, qualitative-style transcripts, and research turnaround in minutes instead of weeks. They differ on the underlying product shape, and that difference matters as soon as your synthetic-human use cases extend beyond a single research task.
This post compares the two platforms on capability, not market traction. We cover persona generation depth, long-interview identity stability, mass-population fidelity, use case surface, report architecture, and parity to real human research. We also include a side-by-side sample interview run on both platforms with identical input, so the differences show up in real output rather than in marketing copy.
TL;DR
iMario and SyntheticUsers both let teams run user research interviews against AI-generated participants, but they are built around different product shapes. SyntheticUsers is a focused qualitative research workflow: define a target participant, run an interview, get an executive report. iMario is a synthetic-human execution canvas where qualitative research is one of six use cases, alongside concept validation, sales rehearsal, content testing, journey design, and AI-agent personality via API. For teams whose only synthetic-human need is qualitative research, both platforms publish comparable parity to real human cohorts. iMario differs in depth of persona configuration, identity stability across long interviews, mass-population fidelity, and report traceability. For teams whose synthetic-human surface extends beyond research, iMario is structurally positioned to serve those task types; SyntheticUsers is not. The question is whether you are buying a research tool or a research-as-one-task-type substrate.
A note on benchmarks: all iMario performance figures cited in this post — identity consistency, mode collapse rates, and parity to real human research — are self-published by iMario. Independent third-party verification of these figures has not been conducted at the time of writing. SyntheticUsers' parity figures are similarly self-reported. Buyers should request the underlying study designs and sample sizes from each vendor before treating either platform's numbers as ground truth. The most reliable signal remains a side-by-side run on your own brief.
iMario vs SyntheticUsers: feature-by-feature comparison
| Capability | iMario | SyntheticUsers |
|---|---|---|
| Persona creation entry points | 3 (brief / LinkedIn URL / personality assessment) 1 | 1 (target description) 2 |
| Persona architecture | Synthetic Individual: Seed + Soul + Memory + Engine + Governance 3 | OCEAN Big Five + 4 input axes (demographics, behaviours, psychographics, profession) 2 |
| Mass population fidelity | Under 5 percent mode collapse at 10,000 personas (published) 4 | Not publicly disclosed 2 |
| Long-interview identity stability | 96 percent at 40 turns (published, vs raw LLM 45 to 62 percent) 4 | Not publicly disclosed 2 |
| Memory architecture | 3 layers + Ebbinghaus decay (working / episodic / semantic) 1 | "Maintain full context across every interview" (mechanism not detailed) 2 |
| Knowledge boundaries | Bounded expertise + "I don't know" defaults 1 | Not addressed publicly 2 |
| Follow-up questions | Host agent autonomously probes mid-interview based on response richness | User-initiated follow-up after the transcript is produced (transcript drill-down) 2 |
| Parity to real human research | 90 percent or higher (decision variance under 10 percent vs matched human cohort) 3 | 85 to 92 percent synthetic-organic parity in independent studies 2 |
| Use case surface | 6 (Discover / Validate / Launch / Optimize / Scale / Build) 1 | Research-focused (qualitative interviews, concept testing, custom scripts) 2 |
| Production canvas | Visual node editor: any content node connects to any audience and output 1 | Fixed research interview flow 2 |
| Agent Skills (executable: send email, review document) | Available (preview) 1 | Not offered 2 |
| Report engine | 5-layer reference graph: codes → categories → themes → findings → governing thought 5 | Executive summary + key themes + verbatim quotes + recommendations 2 |
| Behavioral cues in transcripts | Plain transcript (research-practitioner readability) | Italicized stage directions (immersive presentation style) 2 |
| Free tier | 500 credits at signup, no card, no sales contact 6 | Self-serve signup, no demo required 7 |
| Pricing transparency | Public tier breakdown + per-credit pricing 6 | "$2 to $60 per interview" range, demo to quote 7 |
| API access | Pro tier and above, documented at imario.ai/docs 6 | Available, documented at docs.syntheticusers.com 2 |
When to choose iMario
Pick iMario in any of these situations.
Your synthetic-human use cases extend beyond research. If your team is also exploring sales rehearsal against synthetic prospects, content testing on the same persona pool you use for research, journey simulation, or wiring synthetic personalities into production AI agents via API, iMario is the substrate. The same Synthetic Individuals are reusable across all six task types in iMario's canvas, with persistent memory between sessions. SyntheticUsers does not occupy these surfaces as of 2026-05-06.
Your research design includes long interviews or repeated re-interviews of the same persona. iMario publishes 96 percent identity consistency at 40 interview turns, backed by a memory architecture that separates working memory for the immediate exchange, episodic memory for prior conversations, and semantic memory for accumulated knowledge, with Ebbinghaus-curve decay on each layer. SyntheticUsers' public sample interview is 10 questions and identity stability for longer sessions is not publicly disclosed. If a persona you interviewed last week needs to show up next week with that prior context intact, iMario's architecture is the safer bet.
You need to generate a population, not just one or two users. iMario's persona engine is built for distribution-aware generation up to 10,000 plus statistically distinct individuals, with under 5 percent mode collapse measured against demographic targets. SyntheticUsers' public materials describe per-interview persona generation; mass-population fidelity is not a stated capability. For studies requiring 100 plus distinct personas with documented diversity, this is the dimension that matters.
Your decision-review process needs evidence chains, not just executive summaries. iMario's report engine is five layers deep: every finding traces through themes, themes through categories, categories through codes, codes back to verbatim respondent quote spans and respondent IDs. The architecture is auditable by software, not just by human readers. SyntheticUsers produces an executive summary with key themes and verbatim quotes, which is fast to skim but flatter when senior stakeholders ask "show me where this came from."
You want to evaluate before committing. iMario's free tier gives you 500 credits at signup with no card required — enough to create roughly 25 synthetic individuals or run about 16 short interviews. You can have your first transcript in 15 minutes. SyntheticUsers also offers self-serve signup with no demo required. The comparison worth making is not whether you can get in the door on either platform, but what each platform lets you do once you are inside.
When to choose SyntheticUsers
To stay honest, SyntheticUsers has clear capability fits where it is the cleaner choice.
Your only synthetic-human need is qualitative research. SyntheticUsers' surface is sharper if you do not need anything beyond interviewing AI participants and getting a stakeholder-ready report. The product makes one job easy and does not ask you to think about a canvas or task graph. If your team's research practice is the only place synthetic personas will live, the simpler surface is a feature, not a limitation.
Your team's research vocabulary already runs on OCEAN. SyntheticUsers foregrounds OCEAN as the primary configuration axis — if your team's research vocabulary and stakeholder reports are already built around Big Five terminology, SyntheticUsers' setup maps directly to that language without translation. iMario uses OCEAN as one input within a broader architecture and does not surface it as the primary configuration interface.
You prefer narrative-style transcripts with embedded behavioral cues. SyntheticUsers' default output embeds italicized stage directions throughout each response (shifts in chair, pauses, rubs eyes). For stakeholder presentations where the audience values immersion and the persona feeling embodied, this format reads more theatrical. iMario produces plain transcripts that read closer to real Otter.ai or Grain interview notes. Both are intentional design choices; pick based on what your audience values.
Deep comparison: where iMario differs from SyntheticUsers
1. Persona configuration depth
SyntheticUsers' persona model takes one input shape: a natural-language description of the target participant. The configurable axes are demographics, behaviours, profession, and psychographics anchored in the OCEAN Big Five framework. The platform message is "the more specific you are, the more specific your output." The persona is essentially a richer prompt written by the researcher, processed through the OCEAN model.
iMario offers three entry points to the same Synthetic Individual model. The first is a one-sentence brief ("30 mid-market CFOs, half happy with their current tools, half actively looking to switch"), which triggers distribution-first sampling, diversity validation, and a 9-chapter deep persona synthesis covering identity, narrative, personality, values, stances, quirks, communication style, behavior, and knowledge boundaries. The second is a LinkedIn URL that anchors the synthetic individual in that real person's career arc, domain knowledge, and communication patterns. The third is an 8-minute personality assessment that creates a synthetic twin of the user. All three converge to the same Synthetic Individual cognitive model, structured as five components: Seed (demographic attributes and constraints), Soul (traits, stances, and preferences), Memory (life events, conversation state, running variables like trust and fatigue), Engine (the LLM for language and reasoning), and Governance (consistency checks, safety boundaries, and "I don't know" defaults that prevent the persona from inventing credentials outside its profile).
Behind every entry point, iMario also applies an Expert Reflection layer: a panel of demographer, psychologist, and economist personas is designed to cross-examine each persona output, flagging patterns that may indicate hidden motivations, anchoring biases, or status signaling. Whether this layer surfaces what a trained human analyst would catch is worth testing on your own data before relying on it. SyntheticUsers' public materials do not describe an equivalent layer.
The substantive difference is that SyntheticUsers asks the researcher to describe one user well enough to interview. iMario asks the researcher to describe a population, then constructs the individuals with audited cognitive structure. For a single one-off interview these converge to similar quality. For studies requiring 100 plus distinct personas with documented diversity, or for synthetic individuals you plan to reuse across multiple task types over months, iMario's pipeline is positioned to serve that workload.
2. Long-interview identity stability and memory
This is the dimension where independent academic work has shown the largest variance across LLM-based persona systems. Identity drift, where a synthetic user gradually reverts to a generic AI assistant tone, typically appears between turns 10 and 15 of a multi-turn interview. The failure is not visible at short interview lengths.
iMario publishes a 96 percent identity consistency benchmark at 40 turns, measured against an adversarial probe set that includes contradictions to stated profile, leading questions with the wrong answer baked in, and pressure to abandon stated preferences. The same benchmark measures Claude Opus at 62 percent, GPT at 58 percent, Doubao at 52 percent, and DeepSeek at 45 percent when used as raw chat. The gap widens as interviews get longer. At 60 turns, raw LLMs effectively become their default assistant voice with a thin costume. Methodology is described in the iMario vs Base LLMs benchmark.
The memory architecture behind that number has three layers. Working memory holds the current exchange. Episodic memory holds prior conversation context. Semantic memory holds accumulated knowledge about the persona's life. Each layer decays along an Ebbinghaus forgetting curve, so a persona remembers the conversation you had last week, vaguely recalls the one from two months ago, and has forgotten the small talk from this morning. This produces something closer to how real humans manage time-sensitive recall, rather than perfect-memory or zero-memory extremes.
SyntheticUsers' public materials note that participants "maintain full context and continuity across every interview" but do not publish identity stability metrics for longer multi-turn sessions, do not describe the memory mechanism in detail, and do not benchmark against raw LLMs. The public sample interview is 10 questions, well below the threshold where most identity drift becomes measurable (per syntheticusers.com as of 2026-05-06). This is not a claim that SyntheticUsers performs poorly at depth. It is a statement that the public materials do not let buyers verify performance at depth.
If your research design will routinely exceed 20 questions per session or requires the same persona to be re-interviewed across multiple studies with consistent backstory, this is the dimension to verify head-to-head before signing a contract.
3. Mass population fidelity
For studies requiring more than 50 synthetic individuals, two failure modes show up. Mode collapse happens at generation time: when a model is asked to produce a large population, the outputs cluster around a small set of high-probability templates, so the 1,000 distinct users you asked for end up sounding like 30 versions of the same person. Distribution skew happens when the generated population over-represents majority viewpoints relative to your target demographics.
iMario reports under 5 percent mode collapse at 10,000-persona generation, achieved through distribution-aware seed generation, autoregressive sampling that explicitly tries to make each new persona different from the prior ones, demographic parity checks against real population data, rejection sampling for outputs that cluster too tightly, and an evolutionary optimization stage at scale. The architecture treats diversity as a hard requirement rather than hoping the model gives varied results. Detailed methodology is described in Beyond Average.
SyntheticUsers' public materials describe per-interview persona generation rather than mass-population generation. Mass distribution fidelity, mode collapse measurement, and demographic parity validation are not stated capabilities (per syntheticusers.com as of 2026-05-06). For teams running studies under 50 personas this is unlikely to matter. For teams running quantitative-style synthetic studies at 1,000 plus personas, or building synthetic populations as a reusable asset across multiple studies, it is decisive.
4. Use case surface: research vs canvas
This is the dimension that most clearly separates the two platforms.
SyntheticUsers' product surface is research-focused. The platform supports qualitative interviews, concept testing, and custom script interviews — all delivered as structured research workflows with a report output. The product makes research jobs streamlined and consistent. It does not extend into non-research task types such as sales rehearsal, journey simulation, or AI agent personality via API.
iMario's product surface is a synthetic-human execution canvas. Tasks are first-class objects on a visual node editor: drag any content (a discussion guide, a landing page, an email draft, a pricing table, a support script, an API request), connect it to any audience (a population, a profile, a single individual), connect it to an output shape (report, transcript, scored feedback, API response), and run. The same Synthetic Individuals are reusable across six use case categories: Discover (market and audience research), Validate (concept and product validation, pricing pressure-test), Launch (sales outreach and content testing), Optimize (customer experience and journey design), Scale (sales rehearsal at hundreds of objections until muscle memory is built), and Build (AI agent personality via production API).
Agent Skills (preview) extends this further: Synthetic Individuals can be equipped with executable skills like sending an email, reviewing a document, joining a meeting, or handing off to a teammate. SyntheticUsers does not offer this.
For a team whose only synthetic-human need is qualitative research today, SyntheticUsers' narrower surface is fine and arguably simpler. For a team that has started or is starting to think about reusing synthetic personas for sales rehearsal, content scoring, journey simulation, or production AI agent personality, iMario is the substrate. SyntheticUsers is not in this market category.
5. Report engine architecture
SyntheticUsers' default report is described as "executive summary, key themes, verbatim participant quotes, and recommendations, formatted for stakeholder sharing." It is the standard qualitative research deliverable optimized for fast circulation to product and exec stakeholders. Users can drill into individual transcripts, ask follow-up questions, and annotate specific moments.
iMario's report engine is five layers deep with a reference graph running through it (full methodology in The Five Layers Behind an iMario Research Report). Layer 0 segments every interview response into atomic codes, each carrying a label, sentiment, verbatim quote span, respondent ID, and question index. Layer 1 groups codes per question into 5 to 10 categories with explicit code_id lists; outputs that reference IDs outside the question's code pool are rejected and retried. Layer 2 cross-question themes are derived from roughly 60 categories rather than 4,000 raw codes. The LLM picks category_ids and the graph derives prevalence, sentiment distribution, and cohort breakdowns through deterministic post-processing, so the LLM cannot inflate the numbers. Layer 3 reflexive review computes seven metrics on candidate themes (Jaccard overlap, code coverage, respondent coverage, Gini coefficient of theme prevalence, and others) and routes failing themes back through a critique LLM call. Layer 3.5 produces a Pyramid Principle output: a 2-to-4-sentence governing thought plus 3 to 7 actionable findings, each with statement, implication, recommendation, priority, and at least one theme_id.
Pull on any string in the final report and you land on a verbatim respondent quote with a real ID. The entire reference graph is auditable by software. A QA script can verify every code_id resolves, every theme's prevalence matches its supporting codes, and every finding's theme exists. When a report says "22 of 30 respondents would accept the price with clearer ROI framing," that number was derived from a graph traversal, not paraphrased by an LLM.
The trade-off is depth versus simplicity. SyntheticUsers' single-pass executive summary is faster to consume if all you need is a stakeholder-ready narrative. iMario's five-layer output is heavier in raw structure but harder to challenge when senior stakeholders ask where claims came from. For decision-review-heavy organizations where research findings must survive a "show me why" audit, the deeper format is more defensible.
6. Parity to real human research
Both platforms publish parity claims. SyntheticUsers reports 85 to 92 percent synthetic-organic parity in independent comparison studies and cites supporting peer-reviewed work (per syntheticusers.com as of 2026-05-06). iMario publishes 90 percent or higher parity with real human populations on mindset-driven strategic decisions, where parity is defined as decision distribution variance under 10 percent versus a matched human cohort running the same study (per the Human API methodology).
Numerically the claims overlap. 85 to 92 percent versus 90 plus percent are the same range with different lower bounds. Methodologically the descriptions differ in formality. iMario specifies the variance threshold (10 percent) and the comparison shape (matched cohort, same study, decision distribution). SyntheticUsers cites supporting peer-reviewed work but does not surface the comparison-study methodology on the public homepage.
The honest read is that both numbers represent paired comparisons against real research, both fall in the same ballpark, and both depend on the specific task type, audience, and study design used in the comparison. Buyers should ask each vendor for the underlying study design and sample sizes before treating either number as ground truth. If you have an existing internal dataset that you can compare a synthetic run against, that is a more reliable signal than either marketing number.
Side-by-side sample: same brief on both platforms
The setup
We tested iMario against a 4-line persona spec (Age 29, Austin TX, Product Manager) and a 10-question discussion guide about night-shift work, energy management, and content consumption during shifts. For SyntheticUsers, we used their own public sample interview as it appears on syntheticusers.com — the output they have elected to show potential customers on their homepage. The input conditions are not identical: iMario's output came from a live run against our brief; SyntheticUsers' output is the sample they consider representative of their platform. That asymmetry is worth stating plainly. What the comparison establishes is this: the output SyntheticUsers considers good enough to put on their homepage — against a persona labeled "Age 29, Austin TX, Product Manager" — is a UK hospital nurse with named coworkers, British vocabulary, and zero connection to the Austin product management label it was given. That is not a minor drift.
The intent of giving both platforms only 4 lines is to test what each engine fills in from a deliberately thin label. For iMario this was a live test. For SyntheticUsers this was an evaluation of their chosen public sample — the most direct available signal of what that platform considers production-quality output at a minimal spec. Real research teams rarely write detailed persona descriptions on day one. They describe a target in one or two sentences and trust the platform to flesh it out coherently.
Persona-label fidelity: the headline finding
Identical input. Dramatically different outcomes.
SyntheticUsers' "Austin TX Product Manager" became a UK hospital nurse. From the very first answer:
"I get to the ward around 9:45pm, bit early to get myself sorted before handover at 10. The day staff fill us in on what's been happening with each patient... After that, it's straight into the medication rounds with the nurses. I help get patients settled for the night."
The drift is not subtle. Across all 10 answers the persona consistently inhabits a UK hospital ward with named coworkers (charge nurse Sarah, Jenny), named patients (Mrs. Patterson, Mr. Thompson, Mrs. Chen), British vocabulary (cuppa, knackered, loo, faffing about, rubbish, daft), and even claims to listen to "Radio New Zealand" while supposedly working in Austin. The Product Manager label is gone.
iMario's "Austin TX Product Manager" became a US software PM doing on-call and incident response. From Malik Powell's first answer:
"For me a 'night shift' usually shows up around a release, an incident, or a customer escalation, not like a standing schedule. I'll start by getting a clean picture of the situation, what's breaking, who's impacted, and what 'done by morning' actually means. Then I'm basically in coordination mode: tight Slack loop with engineering, checking logs or dashboards at a high level."
This persona stays consistent across all 10 answers: Slack threads, dashboards, customer escalations, audit logs, queue partitioning, enterprise tenants, release rollouts. American voice, no British dialect, no geographic incongruities. iMario filled the same 4-line label with a coherent, role-appropriate context.
Given identical minimal input, iMario produced a faithful interpretation of the persona label. SyntheticUsers produced a coherent persona that contradicts its own label.
 iMario persona setup screen showing how a 4-line spec is expanded into a Synthetic Individual cognitive model
iMario persona setup screen showing how a 4-line spec is expanded into a Synthetic Individual cognitive model
Voice and specificity
Both platforms produce specific, textured answers. The texture is just different.
SyntheticUsers' James Rivera narrates in stream-of-consciousness, with personal reflection and nostalgia:
"What I really miss is just... normal break time conversation. During the day shifts, people chat about what they're doing at the weekend, their families, everyday things. Night shift, everyone's too tired for proper chat. We just sit there drinking tea in silence half the time."
iMario's Malik Powell answers with operational frameworks and concrete technical specifics:
"If I catch myself rereading the same logs or Slack threads without actually forming a new hypothesis, that's usually a sign my brain's saturated. Same if I start getting overly cautious or, on the flip side, a little too eager to 'just ship a fix' without thinking through the failure mode."
Both readings feel authentic for their respective characters. The relevant question is which register matches the persona label. For a 29-year-old Product Manager in 2026, the analytical register with phrases like "signal quality," "diminishing returns," "I'm not allergic to complexity, I'm allergic to surprise" reads as a real B2B SaaS PM in a research interview. The wistful protagonist register reads as a different person entirely.
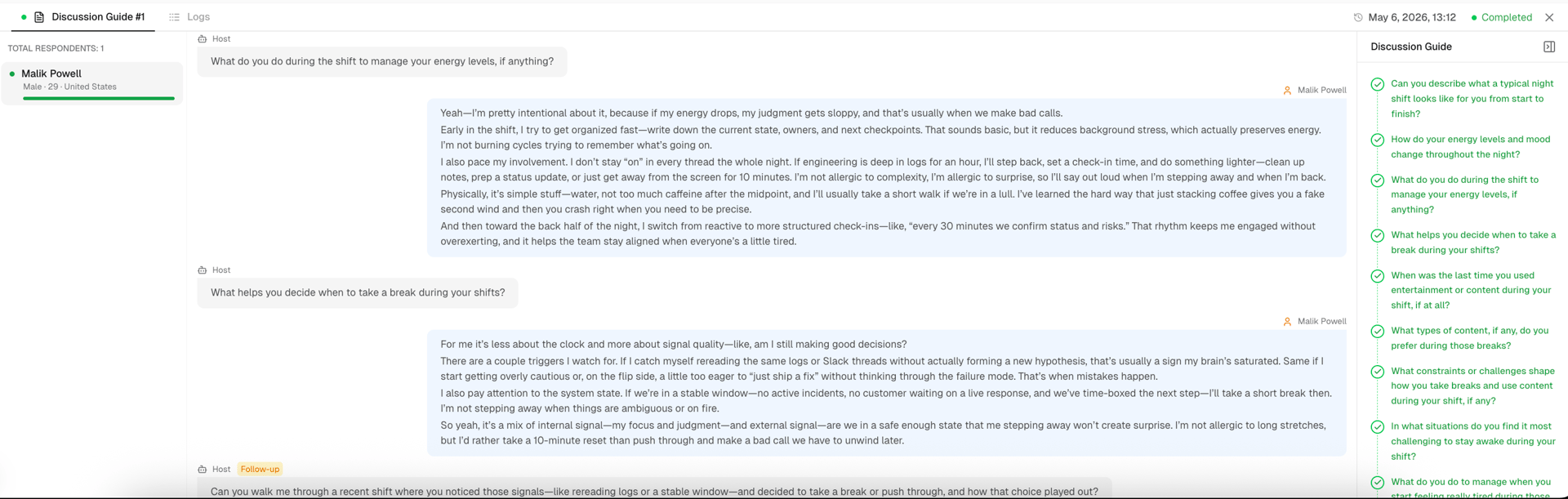 iMario interview view showing Q5 with a follow-up question generated by the Host agent
iMario interview view showing Q5 with a follow-up question generated by the Host agent
Follow-up questions: who initiates, and when
Both platforms support follow-up questions, but the shape is different.
At Q5 of our run, iMario's Host agent did something SyntheticUsers' interview flow does not. It judged the answer warranted deeper exploration and asked a follow-up mid-interview, before moving to Q6.
Host (follow-up): "Can you walk me through a recent shift where you noticed those signals, like rereading logs or a stable window, and decided to take a break or push through, and how that choice played out?"
The follow-up surfaced the most concrete artifact in the entire transcript: a specific incident story about delayed audit logs for enterprise tenants, a reframing moment after a 25-minute break, and a queue partitioning issue uncovered when the persona shared a "specific config path" hypothesis. None of this would have surfaced from the surface-level break question alone.
SyntheticUsers also supports follow-up, but as a post-interview, user-initiated feature. After the transcript is produced, the user can drill into individual transcripts and ask the synthetic participant additional questions. This is useful for analyst-driven exploration: you read the transcript, notice a thread you want to pull, and prompt for more.
The two shapes serve different research moments. iMario's adaptive probe is autonomous during interview execution and surfaces depth without analyst intervention, which matters at scale (running 30+ respondents in parallel, no analyst supervising each one). SyntheticUsers' user-initiated follow-up is more deliberate: the analyst is in the loop on every probe. For research where the value is in unscripted specifics surfaced under realistic interview pressure, autonomous mid-interview probing is structurally different. For research where every probe should be analyst-controlled, user-initiated post-transcript follow-up may be preferred.
Behavioral cues: a stylistic divide worth naming
SyntheticUsers' transcript embeds italicized stage directions every one to two sentences: shifts slightly in chair, rubs eyes, pauses, looks wistful, rubs back of neck. iMario's transcript has none. This is a real stylistic choice and reasonable people will prefer different sides.
Pro-cues: stage directions add an immersive, almost dramatic quality that makes the synthetic participant feel embodied. Some teams find this a useful signal for stakeholder presentations.
Pro-no-cues: real interview transcripts do not contain stage directions. A research practitioner reading 50 transcripts a week may experience the cues as theatrical noise that gets in the way of skimming for content. iMario's plain transcript reads closer to a real Otter.ai or Grain transcript.
Pick based on your workflow. Neither is right.
Report structure
iMario's post-interview report aggregates findings into a five-layer reference graph: codes, categories, themes, findings, and a governing thought. The same Malik Powell transcript above generates a report where each surfaced theme links to the categories that compose it, the codes within each category, and the verbatim quotes plus respondent IDs the codes were drawn from. For a single respondent the chain is short, but for a study with 50 or 500 respondents the same architecture is what makes "show me where this came from" answerable in a decision review.
SyntheticUsers' Report tab on the same homepage sample shows an executive summary, key themes, verbatim quotes, and recommendations formatted for stakeholder sharing. It is a more polished narrative deliverable. It is also a flatter evidence chain.
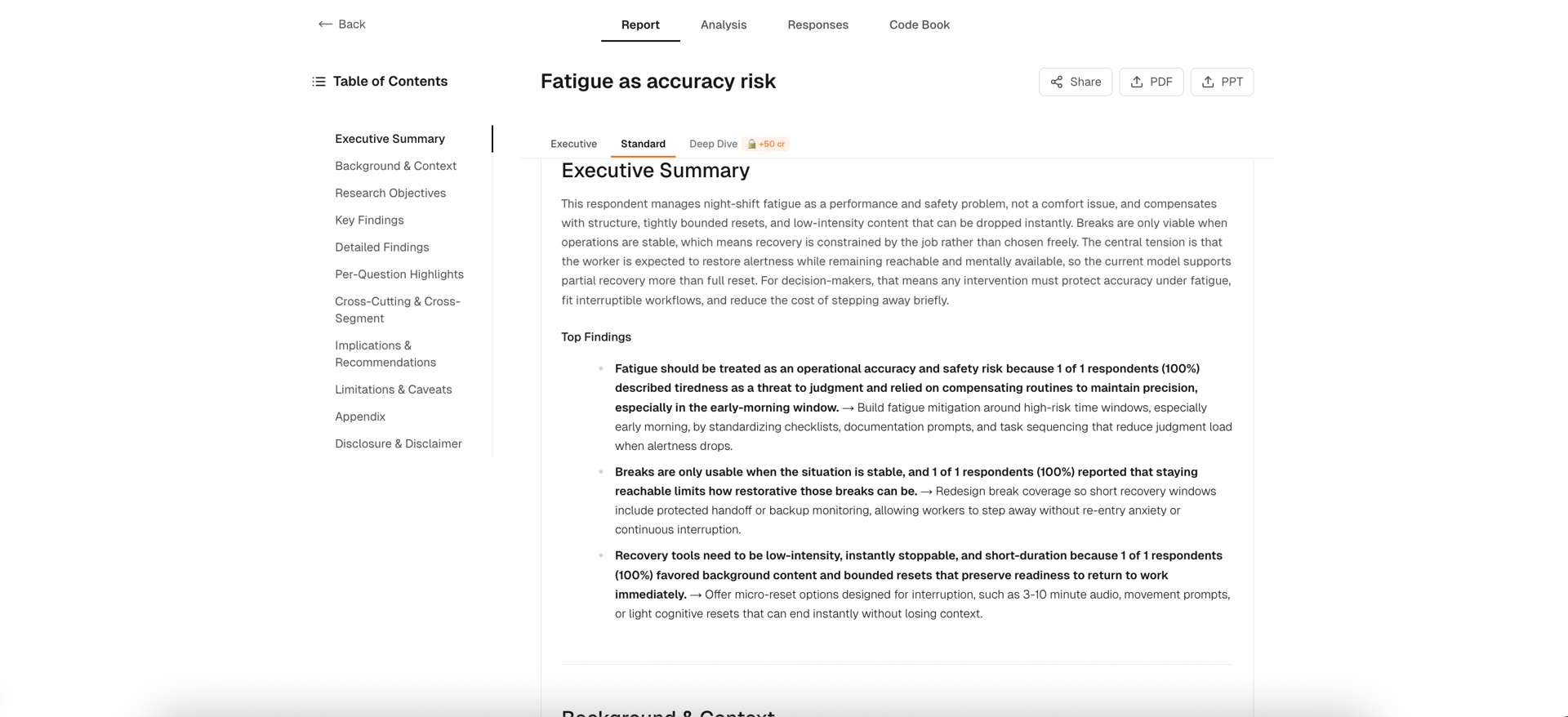 iMario report view showing themes with traceability to underlying coded quotes
iMario report view showing themes with traceability to underlying coded quotes
What this single run does and does not prove
This is one controlled run with minimal input on each platform. The evidence is suggestive, not definitive. A few honest caveats:
- Single trial. A repeat run on either platform might produce a different persona realization. Stable conclusions require multiple runs.
- Minimal-spec stress test. The 4-line input was chosen to expose how each engine handles thin descriptions. With richer specs (psychographics, KB grounding, longer character sketches) both platforms will likely produce better-targeted personas, and the gap may narrow.
- One brief. Night-shift content consumption is a specific topic. A different research question (concept testing, pricing sensitivity, competitive interview) might surface different platform behaviors.
What the run does establish: at minimum-spec input, on a single brief, with default settings, iMario kept the persona label intact and SyntheticUsers did not. If your real workflow involves writing thin persona briefs and trusting the platform to fill in the rest coherently, this is a directly relevant test. If you write rich persona briefs end to end, run your own version of this comparison before deciding.
How to decide in the next week
If you are choosing in the next 7 days, run this minimum evaluation.
- Sign up for the iMario free tier and run one 20-question interview against a persona built for your real research target. Time how long from signup to first transcript. Score the persona's identity consistency across all 20 turns.
- Read the SyntheticUsers public sample on their homepage end to end with the same evaluation rubric in mind: does the persona stay aligned with its label, how does the platform handle specificity, and does the report structure support a decision review.
- Sign up directly at syntheticusers.com and run the same persona description you used on iMario. Score the outputs on the same three dimensions: persona-label fidelity, identity stability across all turns, and whether the report structure would survive a senior stakeholder review.
- Compare the outputs on three axes: persona-label fidelity, identity stability across all turns, and how challenging the questions the synthetic user asks back to the interviewer.
- Pull both reports and ask one senior stakeholder on your team to skim each for 60 seconds and tell you which one they would defend in a decision review.
The platform that wins three of those checks is the right pick for your org, regardless of which one we recommend in this post.
Conclusion
This is not a research-tool versus research-tool comparison where one platform is straightforwardly better at the same job. Both platforms produce qualitative-style transcripts against synthetic users. The sharper distinction is product shape and capability surface.
SyntheticUsers is a focused qualitative research workflow: define a target participant, run an interview, get an executive report. The product makes that one job streamlined and consistent. If your team's only synthetic-human need is research, that focus is a feature.
iMario is a synthetic-human execution canvas where qualitative research is one of six use cases. The same Synthetic Individuals are reusable across research, concept validation, sales rehearsal, content testing, journey simulation, and AI-agent personality via API, with persistent memory between sessions and architecture optimized for the failure modes that show up at long interview length and large population scale. If your synthetic-human surface extends beyond research, iMario is structurally positioned to serve those task types.
For teams currently using SyntheticUsers and looking for an alternative that handles longer interviews, larger populations, or non-research synthetic-human use cases, iMario is the substrate to evaluate.
The most reliable decision signal is the side-by-side transcript on your own brief. Run it.
Try iMario free
Get 500 credits at signup, no card required. Run your first synthetic interview in under 15 minutes.
Footnotes
-
iMario 1.0 architecture and entry points: Introducing iMario 1.0. Synthetic Individual cognitive model components: What Are Synthetic Individuals. ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
SyntheticUsers homepage: https://www.syntheticusers.com/ (as of 2026-05-06). ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9 ↩10 ↩11 ↩12 ↩13 ↩14
-
iMario parity methodology: The Human API: Why We Are Building iMario.ai. Synthetic decision distribution variance versus matched human cohort, threshold of 10 percent. ↩ ↩2
-
iMario benchmark methodology: iMario vs Base LLMs: Solving Mode Collapse and Identity Drift. Across 10,000 distinct synthetic individuals over 40 consecutive interview interactions. ↩ ↩2
-
iMario report engine: The Five Layers Behind an iMario Research Report. Reference graph traversal for prevalence, sentiment, and cohort breakdowns. ↩
-
iMario pricing page: imario.ai/pricing (as of 2026-05-06). ↩ ↩2 ↩3
-
SyntheticUsers pricing page: https://www.syntheticusers.com/pricing (as of 2026-05-06). ↩ ↩2